Demo for feature extraction
Feature Extraction
Feature extraction is a dimensionality reduction. In application for text documents it simply extracts keywords or phrases that constitute topic of the document and may be used in a query to find similar documents or distinguish them in a large population.Demo program at the top shows elementary and effective feature extraction technique for the group of document vectors. The selected group is 3 documents in PATENTCORPUS128. The program builds document-term matrix and adds together the selected vectors and all other vectors. Then Polar Orthogonalization is applied and components with frequent words in selected group are examined.
The coefficient passed to function getFeature defines threshold frequency relative to the maximum frequency. The accuracy can be examined using Qcreener, where the extracted feature can be passed as a query. For example, for the files:
C850P7793356.txt C850P7810166.txt C850P7818816.txt
and coefficient = 2.5, the extracted feature is
measur substrat probe sampl scan
The list of returned documents by Qscreener for this query is shown below
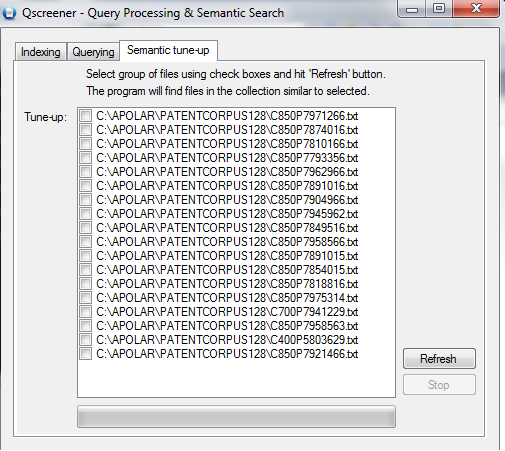
which is very accurate. The files with names starting from C850 belong to the same class. There are 16 files of this class in a collection. They all are returned within the first 18 files in the shown list.



