k-nn test in C#
k-nearest neighbors
Conceptually this algorithm is elementary. When applied for categorization of documents, it process vectors representing rows in document/term matrix. The limited subset of rows must be manually categorized i.e. assigned labels. It is called training set. Other vectors are assigned labels by comparing them to each vector from training set. The decision is made not only by the closest vector but by the small group of nearest vectors (nearest neighbors). The papers explaining k-nn usually show pictures like this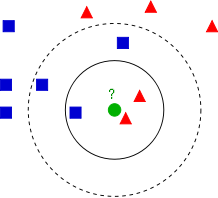
that I borrowed from Wikipedia, where green point is the one that needs to be labeled, blue and red points are already assigned labels. The sequence, in which tested points are selected affects the result, because all categorized points affect classification. The measure of similarity can be chosen differently. In my experiments the cosine works much better than Hamming distance but some papers say opposite. The best number of nearest neighbors in my experiments also contradicts commonly used approach. The best result is achieved when only one closest point is used. The accuracy is 68 percent, test program at the link above. It is better than LSA, pLSA, LDA and worse than Naive Bayes and Hierarchical Agglomerative Clustering.
In order to optimize performance for very large number of documents k-nn needs k-Dimensional tree. The goal of this experiment was accuracy and, on that reason, the k-d tree was not programmed. Those who interested can find k-d trees programs on-line specifically designed to be used in k-nn algorithm. I quickly found this one, for example, but there are more.



