Demo for conceptual proximity
Conceptual Search
Conceptual search or concept search is defined, frequently, as a search performed on a meaning of a word or small group of words that is called concept. That definition, however, is highly exaggerated. Up to this moment there is no computer algorithm capable to understand meaning of a word or group of words. Concept search for TABLE will not return document with a phrase flat surface supported by four legs on the distance of about two and a half feet from the ground or set of numbers organized into rows and columns. The way concept search works is different. The program finds words that are frequently in the vicinity of a word given as concept. Speaking about TABLE, we may expect words PLATE, DINNER, CHAIR and so on. When user inputs the word TABLE as a concept, the program finds the other escorting terms, adds them as extension and execute query with extended set. If in the particular set of documents the word TABLE always is near the name JAMES BROWN, the concept for TABLE for this particular collection will be TABLE, JAMES, BROWN.As it may be clear already, the tricky part is to extract words that are sitting close to concept in the whole text corpus. This search completely depends on format of processed data. The elementary data structure suggested in Inverted File Index allows introduce also elementary, quick, and effective concept search.
The Inverted File Index algorithm is implemented in Qscreener . As a result of processing, the database contains list of files, which names matching the words. The content of each word file is the list of positions where this specific word has occurred. These numbers do not restart at the end of each file but continue through the whole corpus (incremented by large number at the beginning of each file). Having any two word files, the proximity for these words can be identified easily and within few milliseconds, because the files are converted into sorted lists of integers. In my algorithm I compute average distance for the positions that are close and count those that are far. The average distance then adjusted to take into consideration the remote words. The computational demo can be found at the top link. To do the test, any data corpus can be processed by Qscreener, for example, PATENTCORPUS128. Any word from the database can be chosen for the test. In provided example this word is 'microcomput' (it was subjected to stemming). The result is the list of words that constitute the concept of MICROCOMPUT.
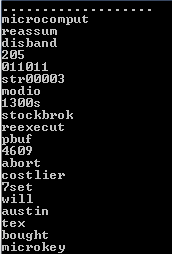
Each of this related words or any group of these words can be than executed as a query and returned results will have big number of the same files. For example, 'disband' or 'microkey' return totally identical list.
When the number of files and size of text data is large, the number of words is between 50,000 and 200,000. It, usually, takes near one minute to identify words related to a concept. Once found, the concept can be saved. It is expected to be stable for data collection and changed only when collection is subjected to significant changes. The concepts can be found for every word from collection. The list can be significantly reduced by removing those words that are met once and those that are considered generic and sitting in nearly every document. For this reduced list of words all concepts can be found for only several hours and used further without spending time on extraction of them.



